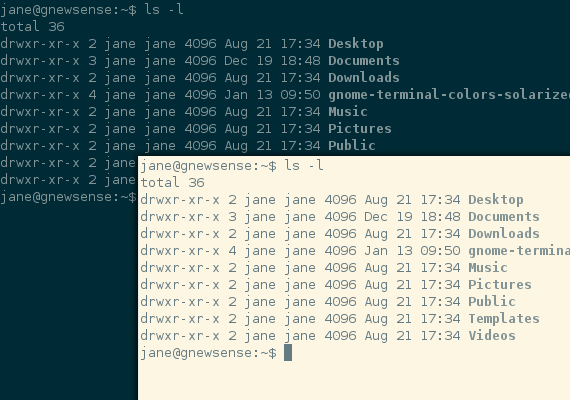
In Emcas if you want to copy a region of text from one file to another then you can just press {C-space} as beginning of copying and then take your cursor to the point till where you want to copy. Then you press {M-w}, M means meta/Alt key and then you will go to the file you want to paste to and put your cursor at the place and press {C-y} and its done. It may look complicated to people who have used Notepad/Wordpad/MS-Office for many years who can just use mouse to copy-paste. Well, it is same except that using keyboard gets much easier over time, plus it kinds of wires into your nervous system. Using mouse to do something never gets easire over time, it remains same.
Now behind the scene, Emacs uses a function called (append-to-buffer) and if you look at the pseudo-code or algorithm, this is how it looks like:
(let (bind-oldbuf-to-value-of-current-buffer)
(save-excursion ; Keep track of buffer.
change-buffer
insert-substring-from-oldbuf-into-buffer)
change-back-to-original-buffer-when-finished
let-the-local-meaning-of-oldbuf-disappear-when-finished
Compare this with how it works in C:
- open file for reading, the file you want to copy from
- if there was no error in step 1 then open file for writing, where you want to paste
- if there was no error in step 2 then check if mark has lower value than point
- use fseek to go to the mark
- if there was no error in step 4 then read/copy one character and write/paste it
- check if copy/pase stopped because of end of work or becauso some error occured in copying.
- check if copy/pase stopped because of end of work or becauso some error occured in pasting.
Here is the code in both languages:
(defun append-to-buffer (buffer start end)
"Append to specified buffer the text of the region.
It is inserted into that buffer before its point.
When calling from a program, give three arguments:
BUFFER (or buffer name), START and END.
START and END specify the portion of the current buffer to be copied."
(interactive
(list (read-buffer "Append to buffer: " (other-buffer
(current-buffer) t))
(region-beginning) (region-end)))
(let ((oldbuf (current-buffer)))
(save-excursion
(let* ((append-to (get-buffer-create buffer))
(windows (get-buffer-window-list append-to t t))
point)
(set-buffer append-to)
(setq point (point))
(barf-if-buffer-read-only)
(insert-buffer-substring oldbuf start end)
(dolist (window windows)
(when (= (window-point window) point)
(set-window-point window (point))))))))
int copy_buffer_richard(const char *w, const char *r, int pf, int pt)
{
int rc = 0;
FILE *fpi = fopen(r, "rb");
if(fpi != NULL)
{
FILE *fpo = fopen(w, "wb");
if(fpo != NULL)
{
int len = pt - pf;
if(pt > 0 && pf >= 0 && len > 0)
{
/* Everything so far has been housekeeping.
The core of the code starts here... */
if(0 == fseek(fpi, len, SEEK_SET))
{
int ch;
while((ch = getc(fpi)) != EOF)
{
putc(ch, fpo);
}
/* ...and ends here. From now on, it's
just a load more housekeeping. */
if(ferror(fpi))
{
rc = -5; /* input error */
}
else if(ferror(fpo))
{
rc = -6; /* output error */
}
}
else {
rc = -4; /* probably the in file is too short */
}
}
else {
rc = -3; /* invalid parameters */
}
fclose(fpo);
}
else {
rc = -2; /* can't open output file */
}
fclose(fpi);
}
else {
rc = -1; /* can't open input file */
}
return rc;
}
/* by Richard Heathfield */
Comparing both, to me Emacs Lisp code is much more easier to understand than C code. C code may look prettier but that is because of lot of extra whitespace around it where Emacs Lisp code in tightly placed. You should look at the pseudo-code of Emacs Lisp on how easier it make connection between pseudo-code and real code. It reads almost like English while C version is, as usual, strikingly odd, pseudo-code and real code look a lot different, typical of C. You may say that comparison is unfair because C is much faster comparing to Emacs Lisp and one file in Emacs Lisp was already opened and I am comparing a full fledged Lisp enviornment with just one single C program. Yeah, I get that, but then again Emacs Lisp code is real code directly taken from source code of Emacs while C code is just written a stand alone, small and short program. Real C program taken from a real life working software will be a lot creepy. In one glance at pseudo-code and real code, you can guess what Emacs Lisp code is doing and it is easier on head whereas real life C code will require lots of glances and will definitely be far from easier on head.
Emacs Lisp version is much more readable and this is a very important point. Ever heard of the sentence called “developer’s time is more important than the machine time” or “a computer program is written once and read 10,000 times” or “Programs must be written for people to read, and only incidentally for machines to execute (Abelson and Sussman, Preface to the First Edition, SICP). Last quote is from one of the most respected books in computer science. If you think those ideas are quite academic or theoretical then you are completely missing the point. Good ideas are not only hard to grasp at first but it is difficult to notice the practical benefit of those too, especially if you are not having few years experience in programming. No matter how much industry is crying about changing customer requirements, good ideas are timeless. These changing customer requirements are nothing but problems that computer programmers solve everday. If, at your workplace, you work mostly in C and C++, you must have noticed almost every company has moved to C++ while two decades back they used to develop mostly in C. More than 65% of the code in this entire world is still in C, but most of it is legacy-code. There is a shift in the thinking that has happened. The programming world keeps on churning out new languages and almost everyone is moving towards the use of languages like C++, Java, Python, Ruby etc. Why is that ? If you look at the new languages, you will notice they were designed more on the side of how to solve the problems in a better way, how can this new language work as a better and improved tool towards solving the problems in or of this world, and indirectly (and may be unknowingly) these language-creators have no interest solving the problems of the machine itself (space and time complexity) because problems of the machine and problems of this world are two points that lie on opposite ends. You can not brilliantly solve the one without ignoring the other by a good amount. C++ was created to solve the problems of large scale software design and hence OO and generic programming paradigms were added. Rather than how to make it more efficient than C, the notion of how to make it better at solving larger problems was choosen. Ruby, Perl, Python and lot of others were created primarily to solve the problems that are not related to machine’s own problems. World is moving from machine towards abstraction. I call it moving to solving problems of this world, moving towards generlization and abstraction, Paul Graham calls it moving from C model to Lisp Model and he is right. Humans always evolve, no matter how many wars and world wars have been fought where humans swore to kill each other, no matter how much negativity and selfishness is there in this world, humans have always evolved and this shift from solving problems of machine to solving problems of this world is a step in further human evolution. Richard Stallman had already evolved to this level by 1984 (along with many other great progrmmers. Good thinking is timeless). He focused more on solving the problem and created this amazing piece of software called Emacs. Thanks to him again.
You should try this book by Robert J. Chassell, it is kind of addictive. When I get some free time it makes me think whether I should entertain myself with a movie or should I just enjoy reading his book 🙂
Originally appeared on arnuld’s blog
![[ Happy Software Freedom Day 2014 ]](https://openclipart.org/image/300px/svg_to_png/202197/sfd2014.png)